A widely circulated prompting technique suggests that instructing AI systems to assume expert roles yields superior responses. While this approach has gained traction among users, recent research reveals that persona-based prompting may deliver less consistent results than previously assumed.
A team from the University of California evaluated 12 distinct expert personas across six large language models, spanning domains from mathematics and software engineering to creative composition and content moderation. Their objective: quantify the performance impact of role-based instruction.
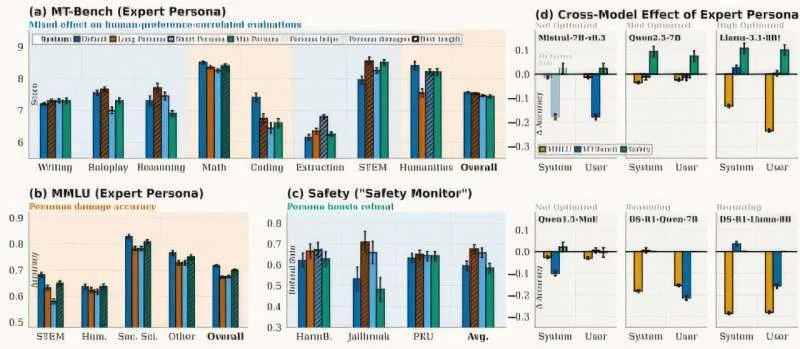
The findings revealed a fundamental tradeoff. While persona adoption enhanced stylistic professionalism and instruction adherence, it simultaneously degraded factual recall accuracy. The research indicates that role-playing prompts trigger an instruction-compliance mode that competes with the model's knowledge-retrieval capabilities, creating a performance tension between form and substance.
What's the solution?
The research team developed PRISM (Persona Routing via Intent-based Self-Modeling) to address this limitation. Rather than applying personas universally or abandoning them entirely, PRISM enables models to dynamically select the optimal response strategy.
The system generates dual responses for each query—one utilizing the model's baseline capabilities, another employing persona-based reasoning. PRISM then evaluates both outputs and selects the superior response based on query-specific performance criteria.
When the baseline response proves superior, the persona-based reasoning isn't discarded. Instead, its stylistic patterns are preserved in a LoRA adapter—a compact model component that the system can reference for future queries requiring similar reasoning approaches.
How did PRISM perform?
PRISM achieved a one-to-two point improvement on MT-Bench, a standardized evaluation measuring instruction-following capability and response utility. The performance gains varied by task category: persona-based responses excelled in creative writing and safety-critical scenarios, while knowledge-intensive queries benefited from the baseline approach.
The research team intends to expand PRISM's persona library and refine its selection mechanisms. While still in early development, this adaptive routing approach represents a meaningful step toward more context-aware prompt engineering.